How it works - Fluentd
日志是计算机系统运行中不可或缺的一部分。随着分布式架构的广泛应用,集中的日志管理已经成为每个系统环境的必备基础设施。过去大家普遍采用的开源方案是 ELK 架构,随着时代的发展,不断地有新的工具涌现出来。Fluentd 便是新一代的日志收集工具,它使用 CRuby 开发,与笨重的 Logstash 相比,显得十分精致、高效。本文将介绍 Fluentd 的架构和功能使用。
Fluentd 的基本架构
Unified Logging Layer
Fluentd 的目标是创建统一的日志层(Unified Logging Layer)。Fluentd 把日志收集过程抽象为三大步骤:输入 → 解析 → 输出。Fluentd 的插件系统非常强大,可以满足用户在每个步骤上的各种需求。Fluentd 就像是一个功能强大的日志中转站,无论什么来源的日志都可以被接收并解析。经过解析的日志,又可以按需求分别用于不同的目的,如存储到不同的数据库,甚至实时分析和报警等。
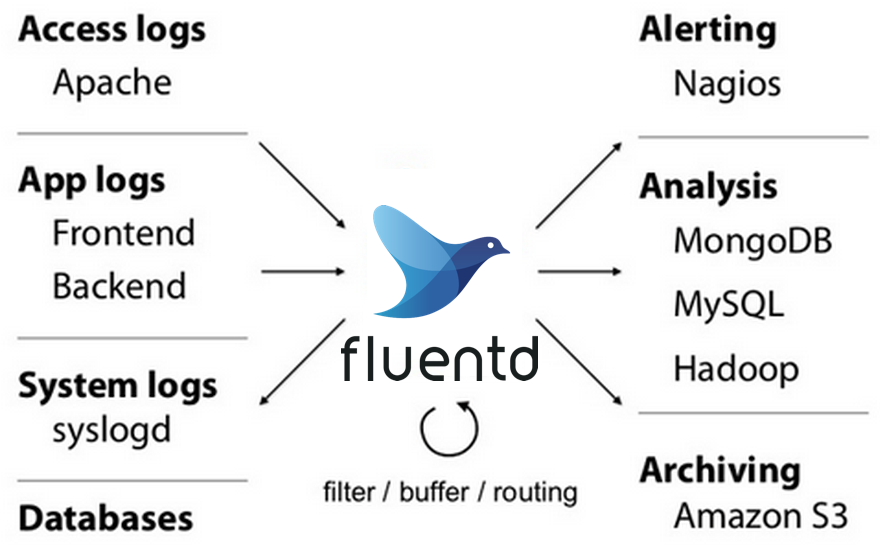
为分布式而生
在 Fluentd 看来,日志不仅仅是能够帮助开发人员排错的工具,日志是能够挖掘出重大价值的重要数据资产。所以日志收集系统的可靠性是相当重要的。Fluentd 提供了 Buffer 机制,日志可以先被写入 Buffer 然后再输出。如果因为下游故障,日志无法输出成功,Fluentd 会不断重试,直到超过用户配置的重试上限。Fluentd 的很多插件还支持负载均衡和故障转移,例如 forward 插件就同时支持 Active-Active 框和 Active-Standby 的高可用模式。
另外,作为所有日志的统一出入口,Fluentd 的水平扩展能力也非常重要。同一个 Fluentd 实例中可以启动多个 worker 进程(默认 1 个),用于分散单一进程的工作量。此外还可以使用 forward 插件将不同的日志路由给下游不同的 Fluentd 实例,以便分散单一实例的工作量。 forward 插件自身还支持负载均衡,也就是说可以同时运行多个相同解析逻辑的 Fluentd 实例。
Fluent Bit
作为统一日志层,我们可能会频繁修改日志解析逻辑,频繁地到每个服务器节点上更新配置文件是不明智的,所以一般情况下,我们会先把每个服务器节点上的日志,汇聚到同一个 Fluentd,把它作为 Aggregator,然后在这个 Aggregator 中配置解析逻辑,把日志发送到不同的目标库中。
此时,我们一般也不会直接在服务器节点上部署 Fluentd,而是选择更加小巧的 Fluent Bit。Fluent Bit 是完全由 C 开发的,基本没有依赖项,运行起来大约只需要 450KB 内存( Fluentd 大约需要 40MB 内存)。
Fluent Bit 与 Fluentd 有着相似的工作原理,但是它主要着力于小巧,所以没有 Fluentd 那么丰富的插件可以选择,也因此功能不如 Fluentd 强大。Fluent Bit 的这个特点,让它非常适合工作在 Fluentd 的上游,只负责从服务器节点中收集日志,将日志 forward 给 Fluentd,由功能更丰富的 Fluentd 来进行解析和分发。
因此,Fluentd 的部署一般如下图
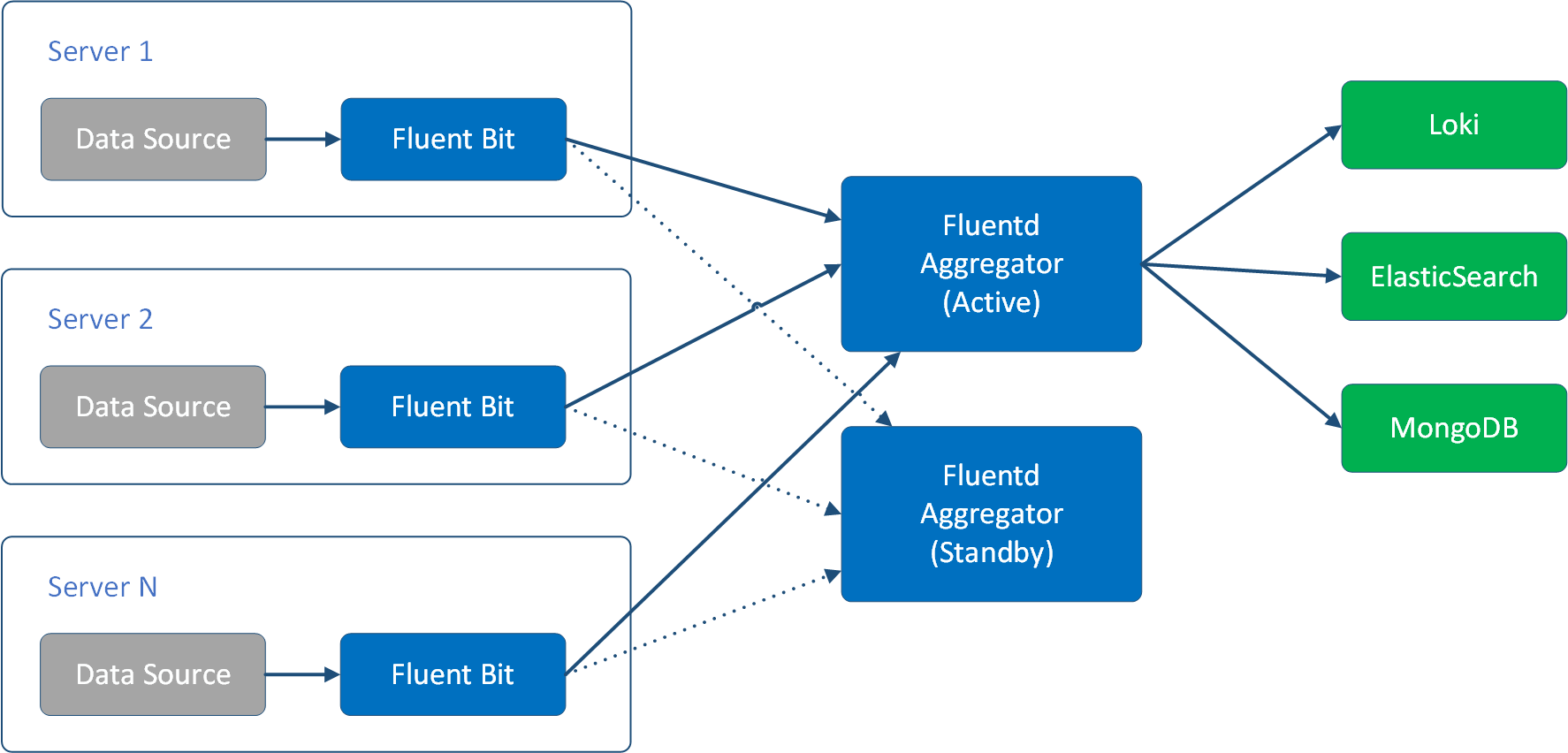
Fluentd 的工作原理
Fluentd Event
Fluentd 中以 FLuentd Event 为概念来处理日志,即 Input 插件获取到的每一条日志会对应生成一个 Fluentd Event。Fluentd Event 包含三部分内容:
- tag,用来表示日志的来源,主要用于路由,用户可以为不同tag的日志,执行不同的处理和输出。
- time,用来表示事件发生的时间,可以从日志内容中获取,默认为日志输入的时间。
- record,一个 JSON 文档,用来表示日志的实际内容。
为了便于理解,首先,我们假设一个名为 run.log 的日志文件中,日志内容如下文:
[2013-02-28 12:00:00 +0900] alice engineer 1
然后,我们配置一个 tail 类型的 source 来读取它,并使用 regexp 插件来解析它的内容。这里的 time_key 和 time_format 十分重要, time_key 表示用 logtime 字段的时间来作为 Fluetnd Event 的 time 字段,Fluentd 会按 time_format 指定的格式来把 logtime (字符串类型) 解析为时间类型。这样 Fluentd Event 的时间就是日志实际发生的时间。
<source>
@type tail
path /fluentd-demo/run.log
pos_file /fluentd/log/run.log.pos
tag run.*
read_from_head true
<parse>
@type regexp
expression /^\[(?<logtime>[^\]]*)\] (?<name>[^ ]*) (?<title>[^ ]*) (?<id>\d*)$/
time_key logtime
time_format %Y-%m-%d %H:%M:%S %z
types id:integer
</parse>
</source>
经过上面配置的解析后,日志对应生成的 Fluentd Event 为:
time:
2013-02-28 03:00:00 +0000
tag:
run.fluentd-demo.run.log
record:
{
"logtime": "2013-02-28 12:00:00 +0900",
"name": "alice",
"title": "engineer",
"id": 1
}
Fluentd 工作流程
不同来源的 Fluentd Event,像数据流一样,根据不同的需求流过不同的 Filter 进行解析,最终流到 Output 后,由 Output 插件发送到目标数据库中。
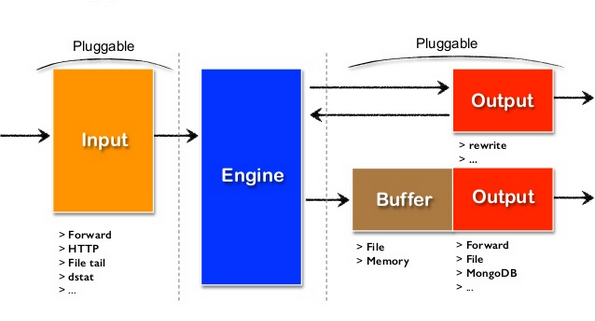
Fluentd 中的 Filter 可以是链式的,用户可以让日志不流过 Filter,也可以依次流过多个 Filter。
Input -> filter 1 -> ... -> filter N -> Output
Fluentd 通过 Fluentd Event 中的 tag 字段实现路由,每个 Filter 都会指定自己愿意接收的 tag,只有 tag 匹配的日志才会被这个 Filter 处理。下面例子中的 run.** 表示所有以 run. 开头的 tag 都会被匹配到。Fluentd 的 tag 匹配模式功能十分强大,比如,我们可以用 run.fluentd-demo.run.log 表示只匹配 tag 完全符合的日志,用 run.* 表示只匹配 run.xxx 的日志,而不匹配 run.xxx.yyy 的日志。更多的匹配模式可以参考官方文档。
在这里,我们使用 record_transformer 插件修改 record 内容,把 Fluentd Event 的 tag 添加到日志中,做为record 的一个字段。
<filter run.**>
@type record_transformer
<record>
tag ${tag}
</record>
</filter>
解析后的 record 内容为:
{
"logtime": "2013-02-28 12:00:00 +0900",
"name": "alice",
"title": "engineer",
"id": 1,
"tag": "run.fluentd-demo.run.log"
}
在 Fluentd 的配置文件中, match 表示 Output,也就是一个 Fluentd Event 的最终去处,Fluentd Event 被 match 处理以后,生命周期便结束了,同一个 Fluentd Event 只能被 match 一次。
match 的 tag 匹配模式和 filter 是一样的,在下面的例子中,我们只是简单地把所有 tag 以 run. 开头的日志打印到stdout,以方便我们观察。
<match run.**>
@type stdout
</match>
值得注意的是经过 match 处理以后,并不代表着日志就一定会消失掉。有时我们会希望将某些日志重新处理,这时可以使用 out_rewrite_tag_filter 插件,这个插件会为符合条件的日志设置新的 tag,然后日志重新开始新的生命周期,重新从头开始被处理。
<match app.component>
@type rewrite_tag_filter
<rule>
key message
pattern /^\[(\w+)\]/
tag $1.${tag}
</rule>
</match>
上面的例子中,我们根据日志中 message 字段的 log_level 来重新设置 tag。
+------------------------------------------+ +------------------------------------------------+
| original record | | rewritten tag record |
|------------------------------------------| |------------------------------------------------|
| app.component {"message":"[info]: ..."} | +----> | info.app.component {"message":"[info]: ..."} |
| app.component {"message":"[warn]: ..."} | +----> | warn.app.component {"message":"[warn]: ..."} |
| app.component {"message":"[crit]: ..."} | +----> | crit.app.component {"message":"[crit]: ..."} |
| app.component {"message":"[alert]: ..."} | +----> | alert.app.component {"message":"[alert]: ..."} |
+------------------------------------------+ +------------------------------------------------+
Buffer
Buffer 是 Fluentd 的重要组成部分,一般情况下,Output 插件都要配合 Buffer 插件使用。
Buffer 主要用于将日志发送到下游之前进行缓存,它在用途主要体现在以下几方面:
- 某些情况下必须先缓存再发送,例如将日志保存到 S3 时,我们必须将日志按固定时间段汇集到一定量后再上传。
- 某些情况下批量发送日志有更好的性能,例如需要将日志写入 ElasticSearch 时,批量写入的性能显然比单条写入要更好。
- 某些情况下受下游系统的限制,必须对日志按时间进行缓存汇集后再发送,例如,老版本的Loki中,不允许写入更老时间戳的日志,我们必须提前一定的时间量缓存数据,等一等时间戳落后的日志。虽然新版本的Loki 放宽了这个限制,但是因为分布式系统中,节点之间的时间不能精确同步,类似的场景还是非常多的。
- 分布式环境下,系统出现异常是很正常的情况,比如硬件故障,网络拥堵,服务器的卡顿等都可能导致日志不能正常发送到下游系统,这时使用 Buffer 可以在出现故障时,自动进行重试,提高可靠性。
Fluentd 提供了 buf_file 和 buf_memory 两种 Buffer 插件,用户可以选择使用文件缓存还是内存缓存,一般情况下我们使用文件缓存( buf_file )
Buffer 内部先将每条日志分别存储到不同的 chunk 中,每个 chunk 中的日志达到一定数量,写满后,才会被交给 Output 插件进行发送。因此,Buffer 内部分为 stage 和 queue 两个区域,还在写入状态的 chunk 在 stage 区中,chunk 写满后,便被转移到 queue 区中,等待被发送。
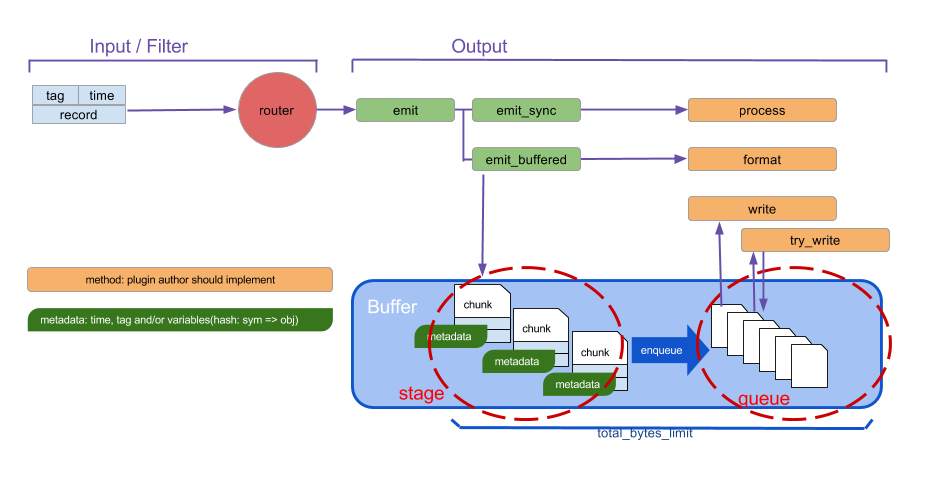
这里我们还以 stdout 为例。
<match run.**>
@type stdout
<buffer tag>
@type "file"
path "/var/log/fluentd/buffer"
flush_interval 30s
</buffer>
</match>
在上面的例子中我们让 Fluentd 按不同的 tag 将日志保存到不同的 chunk 中。 flush_interval 30s 表示每隔 30 秒将 stage 区的 chunk 转移到 queue 区中去发送。所以与前面不使用 Buffer 的时候不同的是,当 Fluentd 启动以后,并没有马上把日志内容打印到终端,而是等待大约 30 秒后才打印。
另外一种常用的方式是,将 tag 和 time 结合起来定义 chunk。
<match run.**>
@type stdout
<buffer tag,time>
@type "file"
path "/tmp/fluentd/buffer"
timekey 1m
timekey_wait 1m
</buffer>
</match>
在这个例子中,我们让 Fluentd 将每个 tag 每分钟的日志保存到同一个 chunk 中。每个 chunk 等待 1 分钟再发送(由 timekey_wait 1m 控制)。为了便于演示我们故意打乱 run.log 中日志的时间顺序如下:
[2023-04-06 14:07:07 +0800] alice engineer 1
[2023-04-06 14:07:06 +0800] alice engineer 1
[2023-04-06 14:07:05 +0800] alice engineer 1
[2023-04-06 14:07:04 +0800] alice engineer 1
[2023-04-06 14:07:03 +0800] alice engineer 1
[2023-04-06 14:07:02 +0800] alice engineer 1
[2013-02-28 12:00:00 +0900] alice engineer 1
[2013-02-28 12:01:00 +0900] bob engineer 2
[2013-02-28 12:01:00 +0900] alice engineer 1
[2023-04-06 13:46:03 +0800] alice engineer 1
[2023-04-06 14:00:50 +0800] alice engineer 1
Fluentd 运行后,我们会发现,乱序的日志被按分钟重新排序输出了,但是 2023-04-06 14:07 中日志的顺序仍然是原来的顺序。
2013-02-28 03:00:00.000000000 +0000 run.fluentd-demo.run.log: {"name":"alice","title":"engineer","id":1,"tag":"run.fluentd-demo.run.log"}
2013-02-28 03:01:00.000000000 +0000 run.fluentd-demo.run.log: {"name":"bob","title":"engineer","id":2,"tag":"run.fluentd-demo.run.log"}
2013-02-28 03:01:00.000000000 +0000 run.fluentd-demo.run.log: {"name":"alice","title":"engineer","id":1,"tag":"run.fluentd-demo.run.log"}
2023-04-06 05:46:03.000000000 +0000 run.fluentd-demo.run.log: {"name":"alice","title":"engineer","id":1,"tag":"run.fluentd-demo.run.log"}
2023-04-06 06:00:50.000000000 +0000 run.fluentd-demo.run.log: {"name":"alice","title":"engineer","id":1,"tag":"run.fluentd-demo.run.log"}
2023-04-06 06:07:07.000000000 +0000 run.fluentd-demo.run.log: {"name":"alice","title":"engineer","id":1,"tag":"run.fluentd-demo.run.log"}
2023-04-06 06:07:06.000000000 +0000 run.fluentd-demo.run.log: {"name":"alice","title":"engineer","id":1,"tag":"run.fluentd-demo.run.log"}
2023-04-06 06:07:05.000000000 +0000 run.fluentd-demo.run.log: {"name":"alice","title":"engineer","id":1,"tag":"run.fluentd-demo.run.log"}
2023-04-06 06:07:04.000000000 +0000 run.fluentd-demo.run.log: {"name":"alice","title":"engineer","id":1,"tag":"run.fluentd-demo.run.log"}
2023-04-06 06:07:03.000000000 +0000 run.fluentd-demo.run.log: {"name":"alice","title":"engineer","id":1,"tag":"run.fluentd-demo.run.log"}
2023-04-06 06:07:02.000000000 +0000 run.fluentd-demo.run.log: {"name":"alice","title":"engineer","id":1,"tag":"run.fluentd-demo.run.log"}
应用实例
下面我们接着上面的例子,介绍一下 Fluentd 的实际工作步骤。Fluentd 为很多系统都提供了现成的安装包,安装过程十分简单,可以参考官方的安装文档 ,这里就不做赘述了。
准备工作
本文中我们使用 Docker 来运行 Fluentd,创建一个假的日志文件 run.log 来进行演示。
# 我们首先创建一个目录,并且切换到该目录下,例如:fluentd-demo
mkdir fluentd-demo && cd fluentd-demo
# 然后创建一个模拟的日志文件 run.log
cat > run.log << EOF
[2013-02-28 12:00:00 +0900] alice engineer 1
[2013-02-28 12:01:00 +0900] bob engineer 2
EOF
基本配置
要运行 Fluentd,需要先为它创建一个配置文件,以指定日志的输入,输出以及解析过程,我们先从最简单的开始,仅指定一个输入和输出。将如下的内容,保存为 fluentd.conf
<source>
@type tail
path /fluentd-demo/run.log
pos_file /fluentd/log/run.log.pos
tag run.*
read_from_head true
<parse>
@type regexp
expression /^\[(?<logtime>[^\]]*)\] (?<name>[^ ]*) (?<title>[^ ]*) (?<id>\d*)$/
time_key logtime
time_format %Y-%m-%d %H:%M:%S %z
types id:integer
</parse>
</source>
<filter run.**>
@type record_transformer
<record>
tag ${tag}
</record>
</filter>
<match run.**>
@type stdout
</match>
在上面的配置文件中,我们定义了一个 tail 类型的 Input(source 标签),一个 record_transformer 类型的 Filter(filter 标签),一个 stdout 类型的 Output(match 标签)。
使用 Docker 启动 Fluentd
docker run --name fluentd-test --rm -it -v $PWD:/fluentd-demo \
fluent/fluentd -c /fluentd-demo/fluentd.conf
可以看到终端中将输出,我们解析后的日志内容:
2013-02-28 03:00:00.000000000 +0000 run.fluentd-demo.run.log: {"name":"alice","title":"engineer","id":1,"tag":"run.fluentd-demo.run.log"}
2013-02-28 03:01:00.000000000 +0000 run.fluentd-demo.run.log: {"name":"bob","title":"engineer","id":2,"tag":"run.fluentd-demo.run.log"}