不可不知的 NUMA 架构
随着虚拟化和容器技术的广泛应用,服务器的配置水平不断提升。如今,一台服务器的内存动辄数百GB,CPU核心数量达到上百也屡见不鲜。过去需要一个机柜才能容纳的服务器,现在可能只需一台就能满足需求。这种多CPU、多任务并行运行的模式,给服务器的架构设计带来了巨大的挑战,于是NUMA(非统一内存访问)架构应运而生。
NUMA架构能够显著提升多任务处理的性能。目前,绝大多数服务器都支持NUMA架构。然而,要想充分发挥NUMA架构的优势,如何高效地使用内存至关重要。正确配置和优化内存使用策略,可以极大地改善系统性能,更好地适应复杂的计算任务需求。
SMP (Symmetric multiprocessing)
在了解NUMA架构之前,我们先来看看服务器是如何工作的。SMP(对称多处理)是一种常见的多处理器服务器架构。在SMP中,每个处理器都是平等的,这里的“平等”是相对于非对称处理而言的。在非对称处理架构中,可能有一些处理器专门负责I/O操作,而另一些则专注于计算任务。目前我们所使用的大部分服务器都是基于SMP架构的。

在SMP架构中,内存是共享资源,多个CPU通过总线共同访问内存。这里的内存是一个统一的整体,对于每个CPU来说,访问内存的效率是相同的,并且所有CPU都必须轮流访问这块内存,这就是UMA(Uniform Memory Access,统一内存存取)。然而,由于现代CPU的速度远高于内存的访问速度,为避免内存访问成为系统的瓶颈,CPU通常会使用高速缓存,并利用复杂的算法来提高缓存的命中率。越高端的CPU,缓存往往越大,但也因此更加昂贵。然而,缓存毕竟是有限的,随着大量不同类型的任务需要并行运行,频繁的内存访问变得不可避免。显然,如今缓存已经无法完全解决内存访问的瓶颈问题。
NUMA (Non-Uniform Memory Access)
因此,为了应对这一挑战,NUMA(非统一内存访问)架构被引入。NUMA架构通过将内存划分成多个区域,每个区域与特定的CPU节点紧密耦合,大大减少了内存访问延迟,从而提升整体系统性能。理解并有效利用NUMA架构,是现代服务器优化的重要一步。
在NUMA架构中,内存不再是一个统一的整体,而是被划分成多个不同的NUMA节点(NUMA Node)。每个NUMA节点包括一个或多个CPU以及一块专属的内存。这样以来,CPU和内存被分成几个不同的逻辑组。对于每个CPU核心来说,有些内存离它比较近,因此访问速度较快;而有些内存离它较远,访问速度则较慢。每个CPU核心优先使用自己所在节点中的内存,从而避免不同CPU核心同时访问同一块内存所带来的延迟。
值得注意的是,在NUMA架构中,内存依然是共享的,每个CPU核心仍然可以访问所有的内存,但通过优先访问离它近的内存并只运行特定任务,能够提高每个任务的运行性能。

在使用NUMA架构的服务器中,一般会通过一条专用的共享通道,让一个NUMA节点中的CPU能够访问另一个NUMA节点中的内存。然而,如果NUMA节点之间互相访问内存过于频繁,这条共享通道就会成为内存访问的瓶颈。因此,为了充分发挥NUMA的性能优势,必须对NUMA节点以及运行的任务进行合理配置和优化。
NUMA 的硬件配置
服务器的内存配置通常受到CPU架构的影响。以 AMD EPYC(霄龙)处理器为例,EPYC采用多芯片模块架构,每个CPU中包含多个“Zeppelin”芯片,相当于将多个子CPU合并到同一个总CPU中。这里的每个子CPU被称为一个DIE。初代的 EPYC 中,包含了 4 个 DIE, 每个 DIE 又有 8 核心,共 32 核心。
在下图的示例中,一个CPU中包含了4个DIE,每个DIE相当于一个多核心的CPU。每个DIE之间通过高速通道(Infinity Fabric)互相连接。
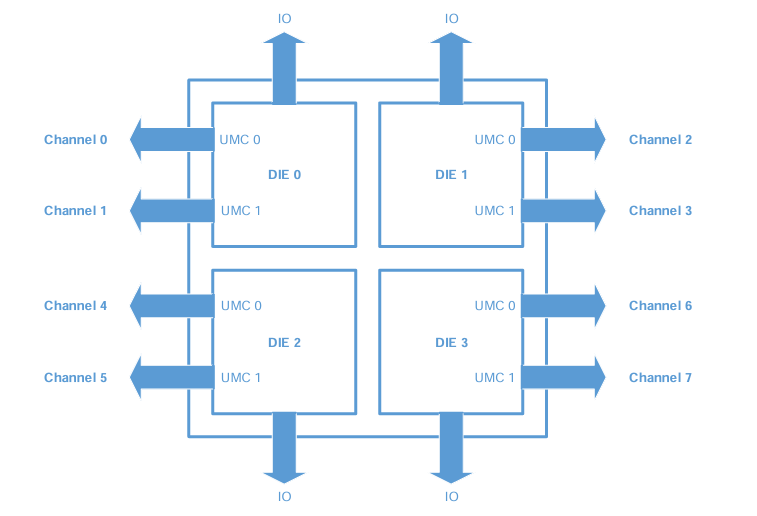
每个DIE都有两个统一内存控制器(Unified Memory Controllers,UMC),每个UMC可以连接两个DIMM内存插槽。如果每个UMC只插入一条内存,则可以实现最大的内存带宽;如果插入两条内存,虽然内存容量增加了,但时钟频率需要在两条内存之间平分,因此内存带宽会减半。一般建议每个DIE至少插入一根内存,因为如果一个DIE没有内存,它就需要通过DIE与DIE之间的Infinity Fabric去访问其他DIE里的内存,这样会比较慢,并且容易成为瓶颈。如果每个UMC都插入一根内存,则可以达到最大内存带宽,也就是最好的性能。
那么,如果让每个UMC通道都配备内存,可以达到最大的内存带宽,这是否意味着每个UMC通道应该是一个NUMA节点呢?
实际情况并非如此。对于每个DIE来说,如果能够同时访问两个UMC,那么内存带宽会翻倍。此外,还需要考虑内存容量的问题。每个UMC的内存容量毕竟是有限的,假如每个CPU插入了8条32G内存,共计256G内存,但是由于NUMA节点的限制,只能访问其中的32G内存,这显然是不合理的。
这就引出了“内存交错(Memory Interleaving)”技术。Memory Interleaving技术,即内存交错技术,可以解决上述问题。例如,如果我们将每个DIE中的两个UMC的内存看作一个整体来使用,不仅内存带宽增加了一倍,内存容量也增加了一倍。EPYC支持四种Memory Interleaving选项:
- Socket Interleaving:当系统中有两个CPU时,将两颗CPU的内存交错成一块内存,用户只看到一个NUMA节点,或者说是没有NUMA节点。
- Die Interleaving:每个CPU中的内存交错成一块内存,用户看到每个CPU对应一个NUMA节点。
- Channel Interleaving:每个DIE中的内存交错成一块内存,用户看到每个DIE对应一个NUMA节点,即每个CPU有4个NUMA节点。
- Memory Interleave disabled:每个CPU有4个NUMA节点,但内存不会被交错。
单从性能角度来看,Channel Interleaving可以提供最佳性能,这也是默认配置,因为DIE内的内存交错最为高效,而DIE与DIE之间的内存交错需要通过Infinity Fabric访问,频繁访问会成为瓶颈。然而,这并不是绝对的,需要根据具体应用场景进行合理配置和优化。
NUMA 的软件配置
目前绝大多数操作系统都支持NUMA架构。在Linux中,我们可以通过 lscpu 命令查看当前系统的NUMA节点情况。
此外,常用的工具是使用numactl来绑定程序运行的NUMA节点。比如,下面的命令将在Node 0上运行my_program:
numactl --cpunodebind=0 --membind=0 my_program
需要注意的是,默认情况下,如果Node 0的内存不足以满足my_program的需求,则程序会因为内存不足而运行出错。因此,必须合理规划应用运行的节点。对于运行数据库等大型应用时,通常推荐使用以下命令:
numactl --interleave=all bigdatabase
这里的 --interleave=all 表示应用在节点之间循环分配内存,其中 all 表示,应用可以使用所有节点。